54. Modélisation des fonctionnalités d’un système
54.1. Présentation d’UML
54.1.1. Historique
UML 1.0 apparut entre 1990 et 1997. James Rumbaugh et Ivar Jacobson rejoignirent Grady Booch afin d’unifier leurs efforts et leurs travaux : les méthodes OMT-2, OOSE et Booch. Leur objectif était de créer un langage de modélisation, utilisable par des humains comme des machines, et capable de représenter entièrement le système à modéliser.
Très vite l’intérêt d’UML a été reconnu et c’est ainsi qu’en novembre 1997, UML 1.1 fut adopté par l’OMG (Object Management Group) qui décida d’en assurer le développement. Depuis, de nombreuses améliorations ont été apportés à UML jusqu’à la version d’aujourd’hui : UML 2.0.
L’objectif n’étant pas de faire un cours sur UML, vous pouvez lire en complément d’informations la spécification d’UML et pour le document pdf.
54.1.2. Pourquoi UML
UML est avant tout un langage permettant de modéliser l’analyse précédent un projet. En proposant un ensemble de diagramme, il permet, en les utilisant, de modéliser l’ensemble des informations nécessaires à la réalisation du projet. De plus, une des caractéristique d’UML est de penser objet dès la phase d’analyse tout en restant totalement indépendant du langage de programmation. Ainsi il permet une analyse objet facilement transposable dans n’importe quel langage objet.
Le deuxième gros avantages d’UML tient dans le fait que c’est un langage normalisé. Il décrit de manière très précise tous les éléments de modélisation et leur sémantique et limite ainsi les ambiguïtés.
Enfin, UML est avant tout un langage visuel permettant de dessiner notre analyse tout en restant rigoureux et compréhensible.
54.2. Les diagrammes de cas d’utilisation
En ce qui nous concerne, nous souhaitons pour l’instant modéliser nos scénarios et nous allons donc nous intéresser plus particulièrement à ce point précis. Il est probable que l’analyse sera ensuite enrichie avec d’autres diagrammes réalisés par les autres acteurs du projet (diagramme de classe pour les développeurs par exemple).
54.2.1. Nos Objectifs
Notre objectif est de comprendre, filtrer et organiser les besoins du client. Il faut ensuite les référencés de manière compréhensible pour l’ensemble des acteurs du projet. De plus, n’oublions pas que notre projet est avant tout centré utilisateur, il est donc très important qu’il soit au centre de notre analyse.
Nous devons donc pouvoir visualiser l’ensemble des utilisations qui peuvent être faites du système et idéalement identifier celles critiques.
54.2.2. Présentation
Les cas d’utilisations, appelés également "use cases", permettent de visualiser l’ensemble des intéractions entres les utilisateurs et le système. Il est cependant important de différencier cas d’utilisation et scénario. Un cas d’utilisation est un client qui souhaite accéder aux informations d’un produit alors que les scénarios seront plus développés en indiquant notamment les conditions requises : s’il est authentifié alors il accède aux données sinon il doit s’authentifier.
Les cas d’utilisation représentent les objectifs des utilisateurs (et donc les fonctionnalités du système) et non les parcours.
54.2.3. Les acteurs
Le terme d’acteur définit les utilisateurs ou les systèmes externes avec lesquels le système modélisé intéragit. Par exemple, notre site Web peut être utilisé par des gestionnaires de contenu, des administrateurs ou des utilisateurs. On peut également envisagé un script php intégré au site permettant de réaliser un dump de la base pour la sauvegardée. Dans ce cas le système ayant en crontab l’appel au script est également un acteur.
On parle d’acteur primaire lorsque le système essaie de réaliser l’objectif de l’acteur. Par exemple, ce sera le responsable du contenu qui souhaite mettre à jour une information. Ce n’est pas automatiquement l’acteur primaire qui initie le cas d’utilisation même si c’est souvent le cas.
On parle d’acteur secondaire lorsque le système communique avec d’autre acteurs. Les acteurs sont représentés par des bonhommes en fil de fer.
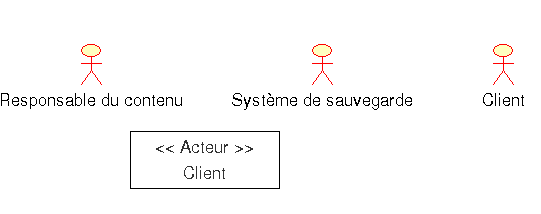
Une autre représentation est celle du rectangle avec "<<acteur>>". Cette écriture est également utilisé de temps en temps notamment pour les acteurs non humains qui serait dans notre cas le système de sauvegarde. De plus, par convention le nom des acteurs commence toujours pas une majuscule.
Il arrive que l’on souhaite être plus précis lors de la définition d’un acteur. Par exemple, on peut souhaiter préciser qu’elle est l’unité de sauvegarde en fonction du type d’action. Lorsque l’on spécifie l’acteur, on parle d’une instance d’acteur. Pour le distingué visuellement on utilise la même syntaxe que pour une classe :
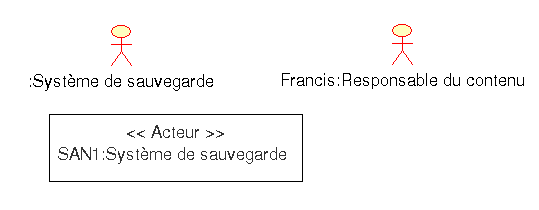
54.2.4. Cas d'utilisation
Les cas d’utilisation représente les besoins fonctionnels à intégrer au système. Pour représenter ce système on utilise un rectangle contenant le nom du système, dans notre cas "site Web". Les cas d’utilisations seront représentés par des ellipses contenant le nom du cas.
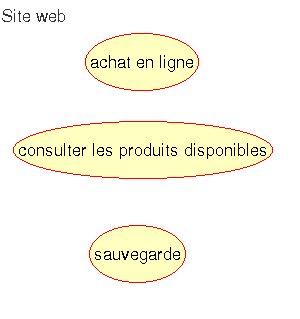
Il est bien évident avec cet exemple que les cas d’utilisation ne décrive que partiellement les fonctionnalités de l’application. En fait on peut voire les cas d’utilisation comme des classes et les scénarios en sont des instances. En effet, un scénario est la réalisation d’une séquence d’intéractions.
54.2.5. Associations de communication
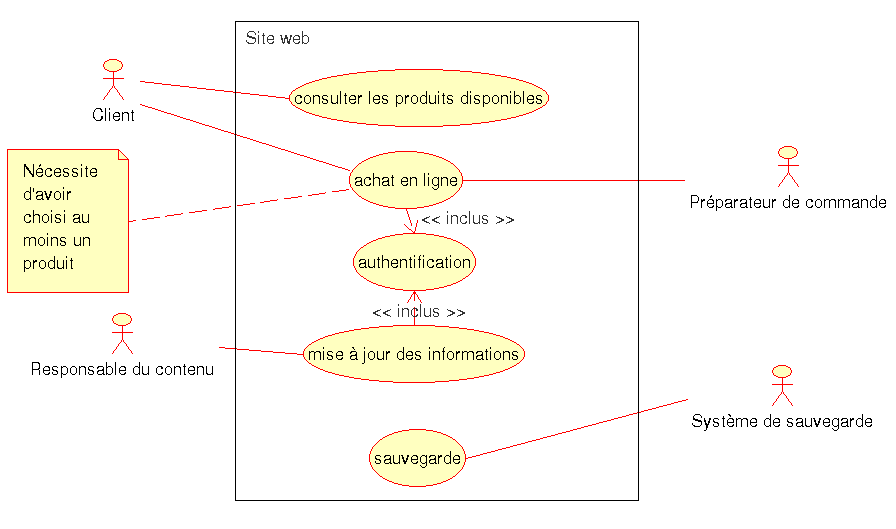
Maintenant que nous avons les bases sémantiques, il est possible de créer un diagramme de cas d’utilisation. Pour cela nous allons représenter les différentes acteurs, le système, les cas d’utilisations et les intéractions existantes. Voici un exemple correspondant à un site Web :
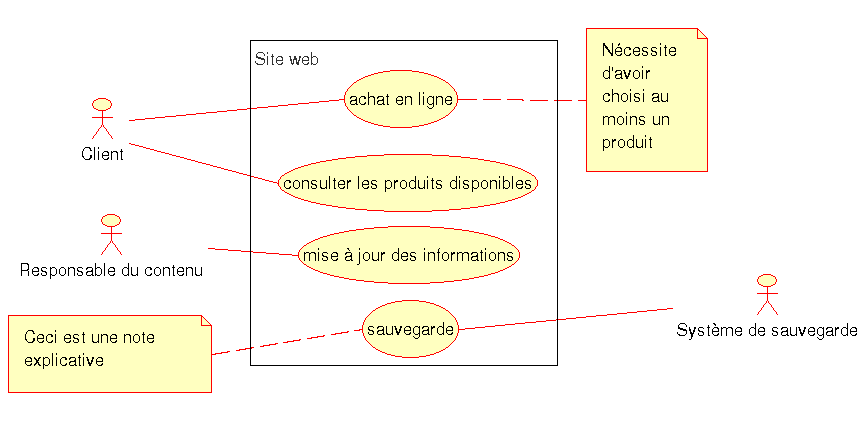
Les liaisons entre les acteurs et les cas d’utilisation représentées par des lignes sont appelées "Associations de communication". Dans certains exemples, une flèche est utilisée à la place d’une ligne pour symboliser celui initie l’intéraction. Dans la majorité des cas, celui qui est à l’initiative est un acteur mais il peut arriver que se soit le système. Dans le cas ou le système est un distributeur de billet, c’est lui qui initiera la connection vers la banque pour vérifier la validité de la carte de crédit de l’utilisateur.
54.2.6. Dépendances
Très rapidement, dans le cas de système complexe, il est possible d’avoir des relations entre les cas d’utilisation. Pour les symboliser, il est possible d’utiliser des dépendances d’inclusion ou d’extension.
A l’utilisation, on se rend souvent compte que ces notions sont plus ou moins bien compris par les acteurs du projet et il est rare que cela facilite le développement. L’objectif des cas d’utilisation étant d’avoir une vision schématique et simple à comprendre, il vaut souvent mieux un schéma simplifié utilisé qu’un diagramme exhaustif et pouvant être mal interprété.
La notion d’inclusion est cependant assez intéressante, et il est possible de l’utiliser de façon claire pour préciser comment un module spécifique sera utilisé. Pour représenté la dépendance d’inclusion, on utilise une flèche pointillée partant du cas d’utilisation principal et allant vers le cas d’utilisation à inclure. Cette flèche porte l’étique "<<inclus>>" qui permet de la différencier des liaisons d’extensions portant la mention "<<étend>>".
Voici un exemple d’inclusion à partir de l’exemple précédent :
54.3. les outils de modélisation
Il est probable qu’au fur et à mesure de la vie du projet, celui ci évolue et de nouvelles fonctionnalités apparaissent. Il est donc important de pouvoir conserver une analyse à jour. La solution papier crayon pour dessiner les diagrammes de cas d’utilisation n’est donc pas la plus adaptée.
Pour modéliser des diagrammes UML, plusieurs outils existes en libre. Umbrello est un de ceux la.
54.3.1. Présentation d'Umbrello
Umbrello est un logiciel permettant de réaliser des diagrammes UML sous KDE. Il permet notamment de réaliser :
diagramme de classes,
diagramme d’états,
diagramme d’activités,
diagramme de séquences,
diagramme de collaboration,
diagramme de cas d’utilisation,
diagramme de composants,
diagramme de déploiements.
Un des gros intérêts d’Umbrello est qu’il permet de générer du code à partir des diagrammes réalisés. De nombreux Ateliers de Génie Logiciel (AGL) permettent de générer du code, comme le code SQL de création de base à partir d’un MLD merise. Umbrello est intéressant car il connaît de nombreux langages comme :
Java,
Php,
Javascript,
Python,
ADA,
Perl.
Il est ainsi possible de générer le squelette des classes, définition des attributs et des méthodes, à partir du diagramme de classes. De plus, les commentaires sont présents dans le code générés. Dans le cas de php, c’est le formalisme de phpDocumentor qui est utilisé. Une partie du temps passé en analyse est donc du temps en moins à passé durant la phase de développement et de documentation.
n.b : un autre outil intéressant qui mérite le coup d'oeil est Bouml. Il est comparable à Umbrello et a été développé par un français. Par contre, il me semble qu'avant cet outil était totalement libre. Pourquoi une licence ?
54.4. Spécifications techniques des scénarios
Nous avons vu que les diagrammes de cas d’utilisation nous permettent de montrer simplement quelles sont les fonctionnalités d’un système. Afin de conserver une compréhension aisée, il est parfois nécessaire d’omettre certaines informations pour ne pas surcharger le diagramme.
De plus, nous avons également remarqués que les cas d’utilisation ne sont pas détaillés et il est nécessaire de les instanciés sous forme de scénarios pour plus d’informations. Nous allons donc maintenant voire comment l’on peut formaliser ces scénarios afin d’avoir une vue plus exhaustive du fonctionnement de l’application.
54.4.1. Exemple de scénario
Pour instancier un cas d’utilisation, il faut choisir un cas le plus proche possible de la réalité, toujours en se mettant à la place du public visé. Si l’on prend le cas d’un achat en ligne, voici un exemple :
"Emilie veut commander un cd pour l’anniversaire de sa soeur. Elle fais une recherche sur le groupe est trouve leur dernier album. Elle décide donc de le commander. Lorsqu’elle vas sur son caddie, elle décide finalement d’en prendre un pour elle également. Elle valide sa commande puis saisie ses authentifiants. Son adresse et ses coordonnées sont affichées. Ils sont correctes et elle décide donc de poursuivre. Elle préfère se faire envoyer les cd’s afin de pouvoir faire les paquets cadeaux et donc garde son adresse pour la livraison. Elle confirme donc la commande puis imprimme le récapitulatif une fois la commande acceptée par le site. Si l’estimation qui lui est fournie est juste, il lui restera une semaine pour tout emballer, pour une fois elle est dans les temps."
Ces scénarios sont intéressants car ils permettent d’avoir une vision d’une situation réelle. Ils permettent d’identifier les actions qui peuvent s’avérer compliquée ou qui pourrait désorienter l’utilisateur. A t’il besoin d’un récapitulatif avant et après l’acceptation de la transaction par le site. Est ce que cela ne risque pas d’être redondant ? Cependant si ce n’est pas fait n’aura t’il pas un doute avant le clique final ?
Cependant, si c’est scénarios sont importants, il n’est pas possible d’en définir un pour tous les cas. Ils sont donc utiles pour vérifier qu’il n’y a pas d’incohérences mais il est intéressant de représenter ces cas sous forme de diagrammes pour faciliter la lecture par les acteurs du projets.
54.4.2. Généralisation
Nous allons donc réaliser un logigramme permettant de présenter toutes les options du cas d’utilisation. Pour cela les états du systèmes seront représentés par des rectangles, et les choix possible par des losanges. Chaque branche partant du losange représente les cas possibles. En développant l’ensemble du diagramme on obtient ainsi l’ensemble des possibilités devant être gérées.
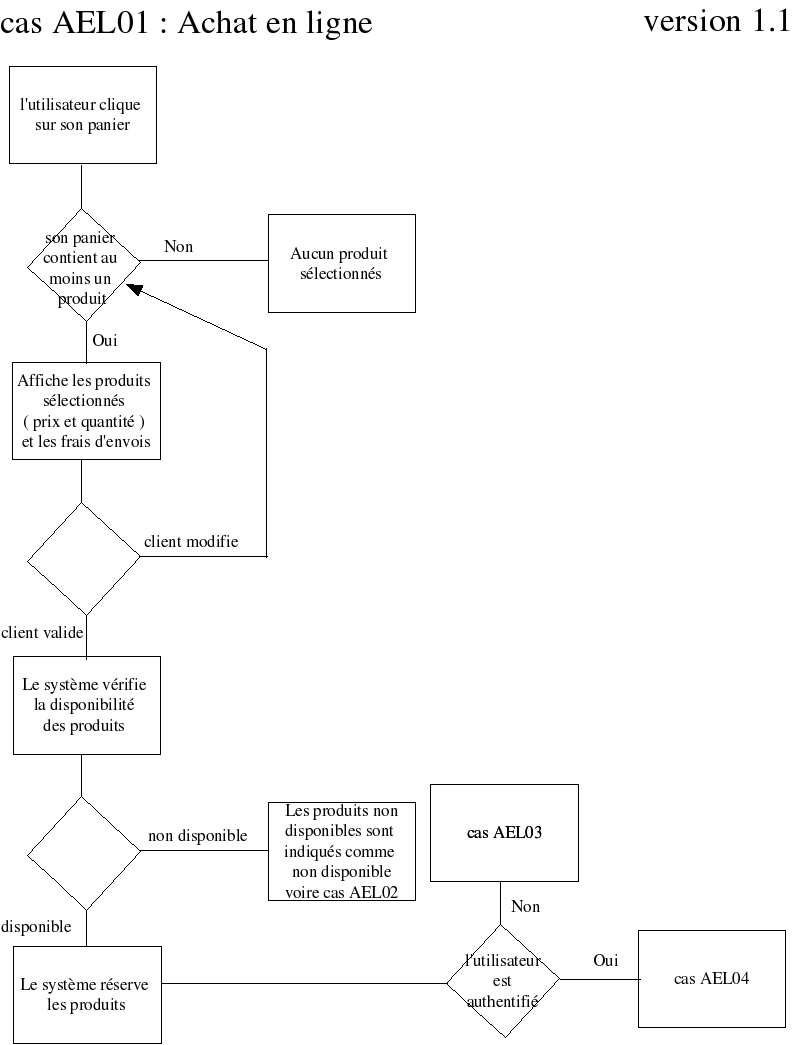
Ce diagramme permet facilement de visualiser tous les cas possibles. Il est donc facilement utilisable par les futurs acteurs du projet.